Engineering an Enterprise-Grade Text-to-SQL Dataset with NeMo Data Designer
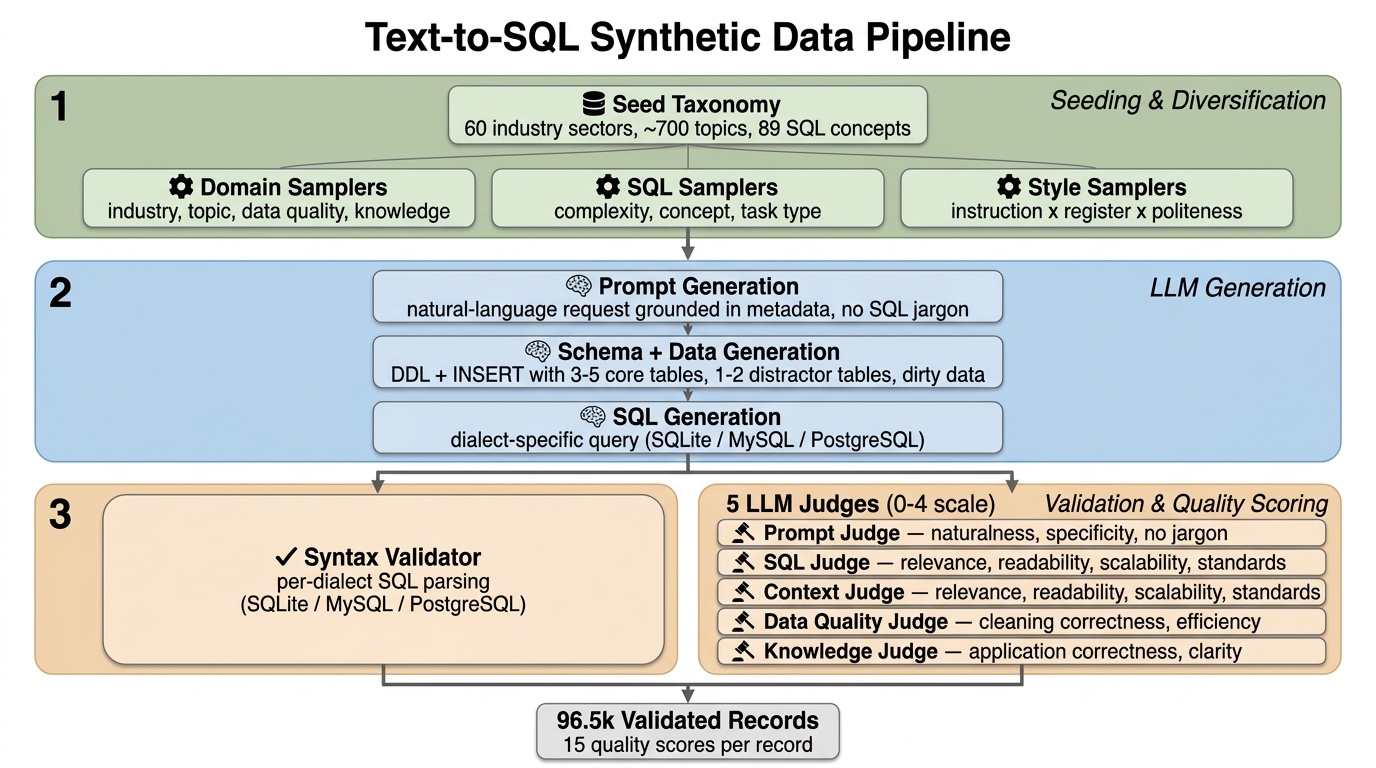
While LLMs have mastered generic coding, Text-to-SQL remains one of the most challenging frontiers in enterprise AI. In many ways this is due to (i) SQL tasks relying on both code and data and (ii) real-world data and databases being quite messy. Focusing on careful data design that accounts for real-world diversity and complexity, we built a NeMo Data Designer pipeline that includes conditional sampling, three-stage LLM generation, code validators, and multi-dimensional judge scoring to generate reasoning-heavy text-to-SQL samples across PostgreSQL, MySQL, and SQLite, and automatically filter down to the highest quality 96.5k records. Each sample pairs a natural-language prompt and a fully synthetic database schema context with a target SQL query. To improve robustness and mimic the messiness of production databases, the pipeline injects distractor tables and columns into the schema context, forcing the model to learn to ignore irrelevant schema elements. The final dataset is validated and filtered through per-dialect syntax validators and five LLM-as-a-critic judges.